i. That the hardware is running correctly,ii. What kinds of things the entry-level participant can look forward to, and
iii. Perhaps a tutorial for getting started.
There may be other applications that I didn't think of, but which
make sense in our broader context.
The team involved in doing this would expect to code up one or more
of these apps, possibly building on code developed in the main project.
iv. Build the Java glue code for new hardware as it becomes desirable to incorporate it in the project, and/orv. Transition the development environment into C++.
My experience is that working in Java offers productivity far exceeding
the cost of extra glue code, but I seem to be in a minority in this opinion.
There is opportunity for a team or subgroup to explore this option, perhaps
by translating the Java code at some (working) stage of the main team's
development into C++ to see how hard it is to work in that environment.
vi. Rewrite Firmata code so it does exactly what we need (and thus eliminate package dependency), and/orvii. Translate some of the hardware currently being added on into Arduino code -- for example, the deadman switch -- into additional Arduino code, probably added onto or replacing the Firmata package.
Either or both of these would require the team so tasked to learn
how to program the Arduino (there are rumors that its compiler is actually
for Java ;-) and develop procedures for installing our custom
code in place of the existing Firmata code.
Post-2018: Colton did a fine job on this. It could be made better better
at error recovery, but everything works well.
viii. A subgroup or small team could be tasked to investigate how to do this effectively, and to determine what kinds of computations can be usefully off-loaded to the GPU.
Post-2018: We learned that the LattePanda does not have much of
a GPU, but the team tasked with this project successfully
developed code to use it.
ix. A subgroup or two could spin off to study the software requirements to implement a MIPI interfaced camera.One possibility is to use a MIPI camera with a USB interface added, which is still somewhat cheaper than what we have. The cameras Steve looked at recently mostly had (uncompressed) YUV coding, for which you can find simple conversions to/from RGB here, and byte ordering here. You still need to develop the necessary Java driver glue -- see item (iv) above to rebuild the drivers.
x. Port our development environment and Java code over to Linux on Pi using (iv) above to rebuild the drivers, or elsePost-2018: The team tasked with this project determined that the project is feasible, but more work needs to be done.xi. Use (v) above to port our development environment and code over to C++ on Linux on Pi.
xii. Design an interactive website to attract prospective group mentors and participants,xiii. Design and implement a startup procedure for bringing another group up to speed understanding the technology, and then adding to it in their own geographical region, and
xiv. Come up with a competition to which the various groups can bring their creations to both compete and share for the benefit of all participants.
I consider all of these options to be significantly harder than
developing autonomous car software in Java on Win10, so there is a substantial
risk that you may not succeed in completing your efforts in the four weeks
of our summer program, but these are all useful things to do for the long
term success of the High School Autonomous Car Project (or whatever you-all
decide to call it), and if you are suitably motivated, you could continue
working on them after the main program ends August 10. Almost certainly
you would have something to show on August 10, and a statement of why it
is useful, and what is left to finish -- sort of the way the Neural Nets
group did last year, except presumably you would actually finish and your
work would become part of the group project next year.
Post-2018: The website is functional, but more work needs to be done.
Any questions or comments? This is your project.
Tom Pittman -- Starting (2018) July 13 through the end of the 4-week
workshop, use the email given on July 16 to reach me.
The industry standard way to have separate teams working on separate parts of a large project and to have their code work together is to define interfaces between the modules, then early on populate them with working code stubs that other teams can depend on and use. The Java language has built-in mechanisms to facilitate this strategy. It did not happen in 2017, and I wrongly supposed that having the simulator support stub versions of the separate tasks would prevent the problem; mechanical fixups are no substitute for good engineering. I recently saw a relevant quote from Aristotle:
Excellence is never an accident. It is always the result of high intention, sincere effort, and intelligent execution; it represents the wise choice of many alternatives -- choice, not chance, determines your destiny.
One of the early problems getting the car to stay on track on the floor
related to the curve radius. If the radius was too tight, the edge of the
track could cross over the center of view before the software started tracking
it, with the result that the software started thinking the track was on
the other side of the taped edge marker, and a nearby light-colored wall
was taken for the second edge. The color of the wall was actually irrelevant
(unless the code was using a full-screen average instead of a track-only
average for determining the white threshold), because the real problem
was not starting in the center of the track. Short-radius turns ran the
track edge across the middle fairly early, and the software needs to be
looking before then to follow it. TrakSim could have made it easy to do
short-radius curves, but I didn't think of it. Maybe next release. Or not.
One important strategy in the development of real-time code is to understand what kinds of code run fast, and what takes a lot of time, then avoid the stuff that runs slow -- or at least move them out of the inner loops. When you have a CPU reference manual and can read the disassembled compiled code, you can see what code is generated by the compiler and how fast it runs. Failing that, it's a little more complicated (but not hard) to build timing loops that measure how long different kinds of code take. I added a timing loop framework to TrakSim (see TimeTest) to make that easier.
Generally, simple arithmetic and logic operations (plus, minus, AND, OR, compare) are very fast, one clock per operation. Multiplication takes longer but most CPUs pipeline the steps, so it counts as one clock. Division cannot easily be pipelined, so it takes several cycles, typically an order of magnitude slower than simple arithmetic, but you can speed it up by pre-calculating the inverse of a divisor, then multiplying. Often multiple operations can be pre-calculated and saved for later re-use. Many compilers do that for you, but you know more about your values than the compiler ever will. The team working on porting the code to a GPU used Aparapi, and most of the things they tell you to do for running on a GPU turn out to be the same things you need to do to make your code faster in the main processor.
Keep in mind that library code -- including new object allocation -- is pretty slow, so you want to keep it out of the inner loops. Your own functions and methods have the same problem, but at least you can look at the code and know. Most IDEs offer metrics for analyzing how long a piece of code ran. The method call itself costs something, perhaps a dozen clocks plus one or two for each parameter passed (plus some extra for object references). Smart compilers will often back-substitute small method code in place of its call to eliminate that overhead and get better optimization on the parameter values. My book The Art of Compiler Design (ISBN 0-13-048190-4) discusses compiler code optimizations at some length. You need to be aware of what the compiler is doing to you, or your timing test code will give wrong answers. You will see that some of my example TimeTest code failed to get past the optimizer. They work a lot harder at it now than when I wrote the book.
The real killer this year was going through every pixel of the input image multiple times. You need to do it once to convert the Bayer8 data to RGB. If you can capture at the same time all the other forms in which you need that data, it will be faster. Loop overhead is pretty small, but array access requires several machine instructions to compute and range-check the index, to test the array object for null, and then to index into it, typically between 5-10 machine instructions. Caching array values rather than going back to the array several times is faster. The compiler might do that for you, but it might not. Multi-dimensioned arrays require that for each dimension; doing your own subscript calculation into a single-dimensioned integer array is much faster. Object access is like array access, but without the range-check code. If you can open up your object into a small number of sequential integers in a huge integer array, the code will not only run faster (because small fixed offsets from a single array index are free in most hardware and a smart compiler will group them into a single range check) but also be better portable to a GPU (because the OpenCL GPU interface used by Aparapi does not do Java objects). Keeping the data that is to be processed together close in the same array will reduce cache faults both in the GPU and also in the main processor.
You might be able to parallelize the code a small number (one or two
or four) of pixel lines at a time in separate processes.
Gaussian blur is an example of the same kind of thinking. The common name for a Gaussian distribution is "normal curve" (or sometimes "bell curve" for its shape). It was long ago observed that a black or white dot in an image that is out of focus has a density function that resembles the bell curve, so the PhotoShop tool that has that effect was named "Gaussian blur" instead of (more accurately) "defocus." The term is inaccurate because the radius of the photographic (and PhotoShop) blur is determined by the diameter of the (actual or implied) lens aperature, whereas the radius of the bell curve is technically infinite. But in computers we mostly only deal in approximations of the real world, and the "Gaussian blur" tool is at best only an approximation to the blur that results from a defocussed lens, and an even worse approximation of the bell curve that gave it its name.
When you understand that, you can safely make other approximations that get your result much more quickly -- as the matix definition of Gaussian blur did for PhotoShop, which being a localized computation, can be off-loaded into the GPU for very fast computation. In our case, there is a very fast way to get the same kind of approximation to the blurring effect so that speckled images can be smudged into something smoother. That's what we really want, not two-dimensional mathematical perfection (which in this case would be incorrect anyway). The simple fast (one-dimensional) blur can be accomplished by adding up the pixels in a single row, but degrading the previous sum as you go. It costs you a couple of adds and a shift, which is very fast -- and speed is important when you have a third of a million (or more) pixels to do. The result is essentially an integral of the neighboring pixels (like the "I" of "PID"). The matrix method you find on the internet involves eight or 24 floating-point multiplies -- which, because PhotoShop does it that way, the hardware people worked very hard to make it happen fast in a GPU -- and that still limits the blur to a radius of one or two pixels. The running sum method spreads the effect out to infinity (or at least to roundoff error, perhaps six or eight pixels instead of one or two), and with far fewer operations (so it's faster).
The running average method of smoothing the data can be applied with a longer memory by adding three or seven times the preceding value then shifting the sum two or three places (instead of one). This way you can get both despeckling (with a 1:1 or 3:1 sum) and also a long-term (7:1 or 15:1) average to compare new values to as a properly despeckled edge detector that still tracks luminance gradients across the track. I added a strong luminance gradient across the track near the starting position in the "PSU Stairwell" track for you to practice on. See also "Pebbles with Gradient" below.
Similarly on a more local level, the team identifying stop signs and
traffic lights rather cleverly adapted last year's blob detection code.
Unfortunately, that code did a lot more work than we needed this year,
and that extra work came at a stiff price. Often over the years, I was
asked to extend an existing product's code to add features or functionality,
and more often than not, I would tell my client that I would "hang [the
previous version] up on the wall for inspiration," but otherwise ignore
it and rewrite the whole thing, and it would cost them less and work better
than my trying to re-use the previous code. Re-usable code is great when
compute time and memory space are free, but many interesting computational
projects have constraints which encourage idea re-use, but not code. When
dealing with real-time systems where performance makes the difference between
success or failure (like our autonomous car), we need to be prepared to
rewrite what needs rewriting. As an example, I tried my hand at blob detection
suitable for finding traffic lights and stop signs. I left it in the DrDemo
GetCameraImg()
code so you can compare it to the best you can do. I think you can do better.
Notice that most of the work in my code is done in the single pass through
the pixel array, and it only looks for red, green, and yellow blobs above
the horizon.
Using multiple cores in the CPU effectively requires that the separate threads do not depend on each other. For driving the car, the steering code is most time-critical, it must have visual information about the track as soon as possible. This means that the primary thread which accepts the camera data must deBayer it and convert it to the luminance image needed for steering and pass it off to the module that makes the steering decisions, all in a single thread (because thread management takes time). For additional speed, this process can look at only the half of the image below the horizon, and delegate the above-horizon half of the image to another thread. A third thread can be waiting off to the side, to assemble the RGB image and any presentation information from the other processes for display on the screen. This approach has two or three separate threads deBayering the two separate halves of the image, but that could be done in parallel.
When (or if) you get a real GPU to work with on the car, it makes sense to slice the pixel processing below the horizon up into individual lines and send them off to the GPU separately, or to separate cores of the main CPU if you have more than four cores. Blob detection above the horizon is not so easily subdivided, because you need to carry context from across the image in both dimensions.
The speed control work is taking time to find blobs -- and eventually pedestrians -- and to plan the acceleration and stopping requirements, but the timing is not critical, because basically a stopped (or soon to stop) car has all the time in the world, so this can be done in a lower-priority thread. Posterizing the pixels is pretty quick -- I counted a nominal maximum 44 machine cycles (= 22ps in a 2GHz CPU) through my implementation, slightly less than the cost of deBayering -- and my "speedy" blob-finding code spends most of its time on uninteresting pixel colors, about the same per pixel as posterizing. By restricting the "interesting" colors to (stop sign) red and the traffic light colors, the number of blobs to process is quite small -- perhaps greater in the real world, but still less than half the possible colors -- so the N2 processing time to merge blobs is greatly limited. Those benefits disappear when you start looking for pedestrians, so the separate thread -- and possibly also splitting the processing across multiple frames as needed -- rescues the total frame rate.
Similarly, there was an effort to memorize the track for the purpose
of planning a racing curve through the turns. This involves a lot of processing,
but it also can be off-loaded into a separate thread that does not need
to keep up with the frame rate. You do not want to be continuously spawning
and destroying threads, but rather (like object creation) start up all
the threads you need at the beginning, then use semaphores and transfer
data (better: events sent to the thread's event loop) to get it started
on the next chunk of processing. This allows the additional threads to
run asynchronously with respect to the frame rate, which is in the one
time-critical thread.
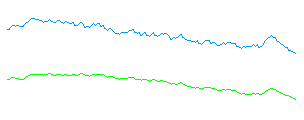
Notice that the white line in the shadow end (the bump on the right) is not brighter than the darker pavement in the light (the left end). You can do a 3-bit smoothing function (n+p*7)/8 to get this curve (blue), which is not much help. Here also is a 4-bit smoothed curve (green), which in some ways is even worse:
What you really want to do is keep a short history (circular buffer)
of the running averages, so that you test the new smoothed value against
what it was a short while ago to detect a steep rise (now smoothed to a
shallow rise) as the edge of the white line: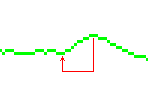
The half-life rise time for an n-bit smoothing function is about half of 2n steps, so if the white level is 32 units brighter than the lightest pebble in your pavement (or carpet, as the case may be) and the pavement pebbling has a dynamic range of 32 units, then a 4-bit smoothing function will take eight steps to rise half the way from pavement to white line, but similarly it will take eight steps to meander halfway across the pebble range; another eight steps takes it another half-way (to 75%) so your circular buffer only needs to be length 2n to span 75% of any short-term change (the red arrow).
Rev. 2019 March 1 (video link added 20 Feb.13)